AMD显卡畅玩本地大模型
PS:很久之前写的一篇体验文章啦~ 测试一下hexo的博客功能~
为什么选择AMD
因为穷(bushi✘),广大的DIY玩家因为各种各样的原因选择了AMD显卡,让我们相聚于此。AMD显卡相较于NVDIA以其高性价比著称,奈何NVDIA早已建立起CUDA的壁垒,AMD显卡在人工智能领域“有劲使不出”或者算力较NV差。几个月前,Ollama支持了部分AMD Radeon显卡以及AMD Radeon Pro显卡,让广大玩家有了尝鲜的机会,接下来咱们展开说说
什么是Ollama
“畅玩”之前,咱先把简单的原理搞清楚。
Ollama gihtub:https://github.com/ollama/ollama
Ollama官网:https://ollama.com/(可正常访问)
什么是Ollama?
——Get up and running with large language models.
Ollama是一个调用和运行大模型的工具,可以是官方提供的大模型,也可以是非官方提供的途径,非Ollama官方提供的大模型可以前往Huggingface和魔搭社区(可正常访问)下载。
几个月前,Ollama官方终于支持了Radeon、Radeon Pro、以及AMD Instinct显卡👍👍👍这使得安装有AMD显卡的计算机在使用Ollama推理大模型时能够直接使用GPU而不是CPU推理
==目前官方支持的显卡如下==

Let’s start
首先是下载Ollama客户端

单击下载好的OllamaSetup.exe文件,Ollama会安装在默认位置,无需选择。
需要注意的是,Ollama并没有提供图形化(GUI)的操作界面!!!因此,安装完成后Ollama将在后台运行,模型安装、对话等等交互都在终端中完成
对于A卡用户,这根本难不倒他👍
Ollama官方提供了多种模型,如llama3.1,qwen2,并列出了一键式安装方法。
此处以最热门的llama3.1为例
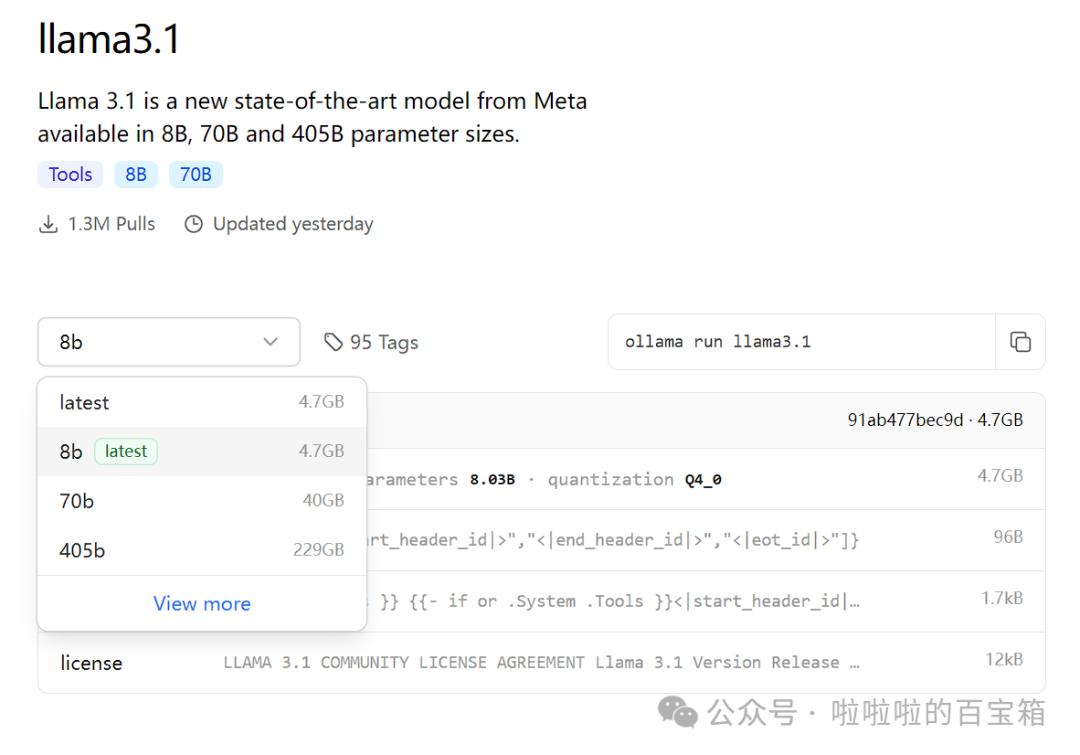
默认提供的是8b模型,大小4.7GB,这对于大多数的Radeon显卡的显存来说都是够用的,8b指的是参数大小,b即billion,此模型有80亿参数。llama3.1也提供了更多选择,若显存更大或者多张显卡交火也可尝试更大的模型。
复制右边的一键运行命令(ollama run llama3.1)
接着打开Windows终端,比如Windows PowerShell
打开开始菜单或者按下Win徽标键,搜索powershell即可找到。
在终端中输入ollama run llama3.1,相应的8b模型会被下载下来(可正常拉取),速度取决于网速,一段时间下载完成后将自动调用模型,即可与大模型对话。
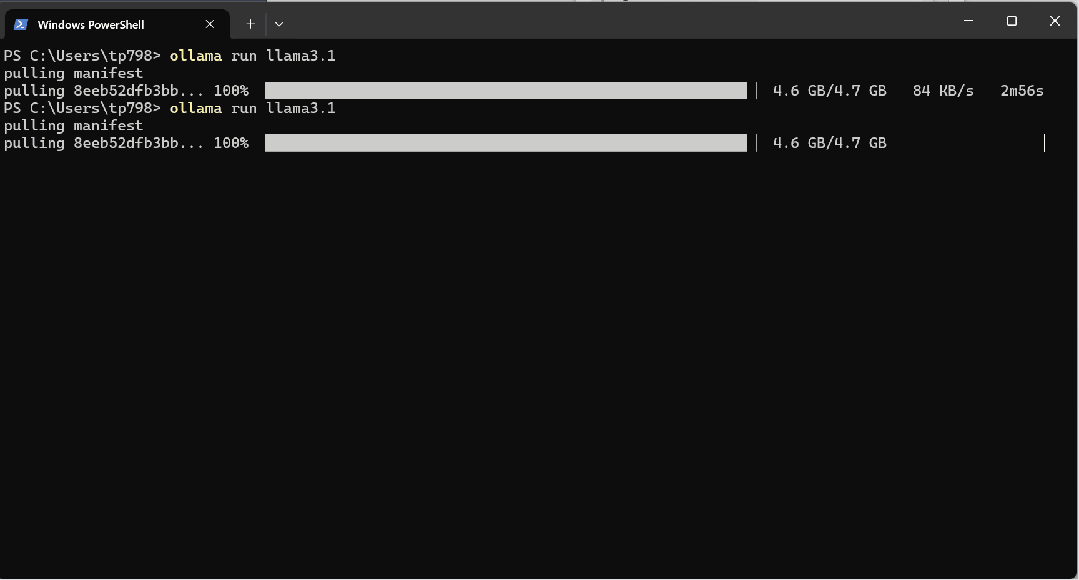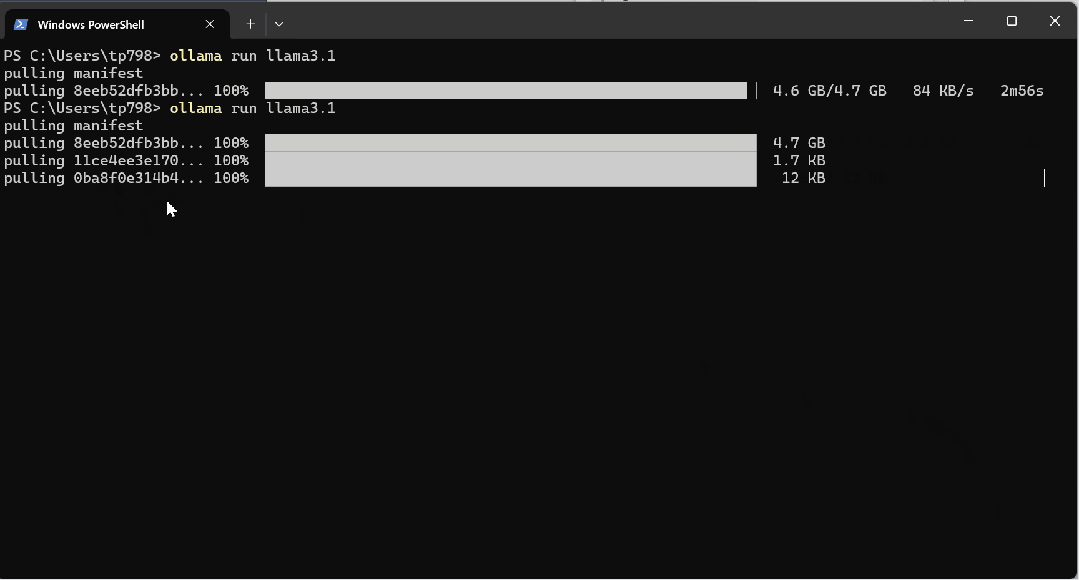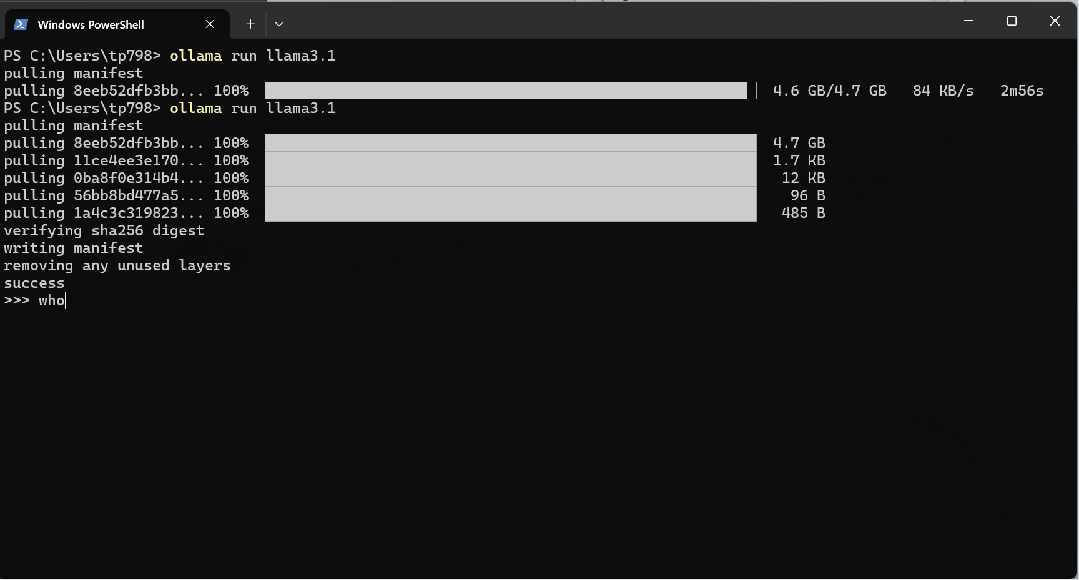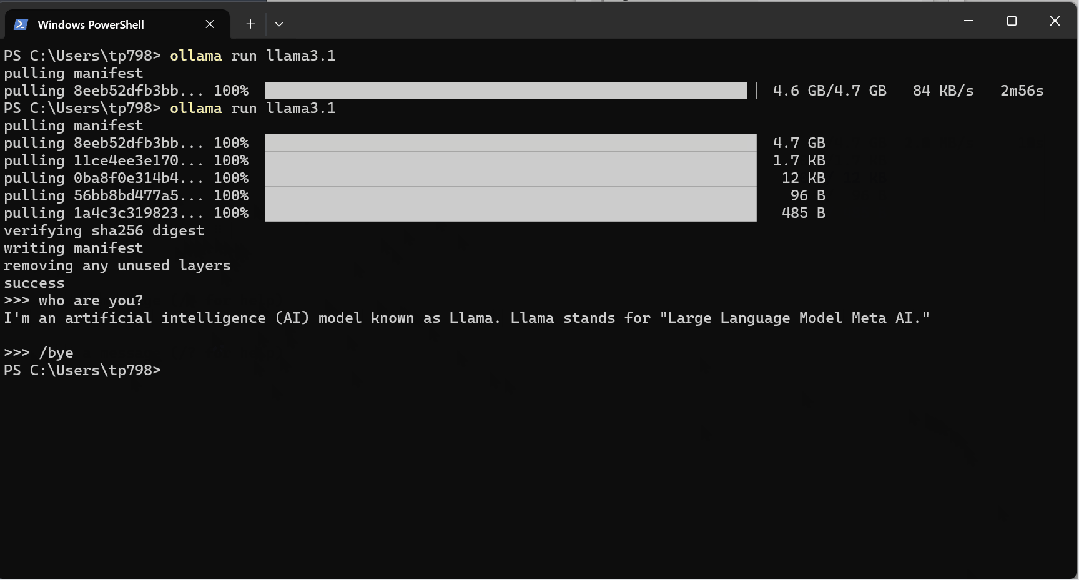
下载完成后,当看到“>>> ”符号时即可与大模型对话,输入“/bye”退出
笔者使用的是Ollama官方并不支持的AMD 780M核心显卡,因此推理(可理解为对话后文字的返回速度)由CPU完成,速度还行,可以正常接受。
各位读者的计算机上GPU的推理速度一定比CPU快得多得多
后话
除了Ollama官方提供的模型外,Ollama也可以使用从Huggingface或者魔搭社区(可正常访问)下载模型,分为GGUF和PyTorch or Safetensors两种。
前者的操作如下,而后者通常对硬件设备(显存)要求更加严格

原文链接:https://mp.weixin.qq.com/s/u9RMrjh-_NJmMR7A4XFVBw